Learning AI Poorly: Transform music into "pictures" so AI can do its thing
(originally posted to LinkedIn)
Say you want an AI that can identify cats… I think by now we all sort of know that you just have to create a fresh neural network (everything in it is set to random numbers) and then train it by feeding it a LOT of pictures of cats.
![]()
When you’ve finished training, you can feed it a new picture and it will output a probability that the picture was of a cat. Using more advanced, generative techniques, we can create a neural network that, once properly trained, can create brand new pictures that… look like cats.
Generative AI, man… It is absolutely bonkers, but seems like text and image generation is common enough that it isn’t quite as magical anymore. I mean, a picture is just a grid of numbers and trained neural networks are really good at picking the best numbers to put into that grid to trick us into thinking we are looking at a cat. A similar thing happens with strings of words, ChatGPT and all that.
But what about music? The format is nothing like a two dimensional picture and therefore nothing like a grid of numbers. It might be a bit closer to a stream of words, but even then text is more one dimensional. With music there can be a whole orchestra and drums and someone singing on top. How can you get a thing that’s good at picking numbers to trick us into hearing a complicated song? Easy. You transform it into something an AI is good at.
Short Time Fourier Transform (STFT) #
What if I said you can take audio (or almost any signal) and sort of splay it out in a way that separates the high and the low parts, the thumps and the psssssts, the bleeps and the bloops into a picture. Better yet, what if I said you could take that audio, transform it into this “picture” and then reverse that transformation right back into the original sound. Do you think you could train a neural network using those pictures? Sure! Why the hell not?
Instead of trying to explain the math behind Fourier transforms, let’s have some fun and watch this video of Ariana Grande’s studio vocals transformed via STFT:
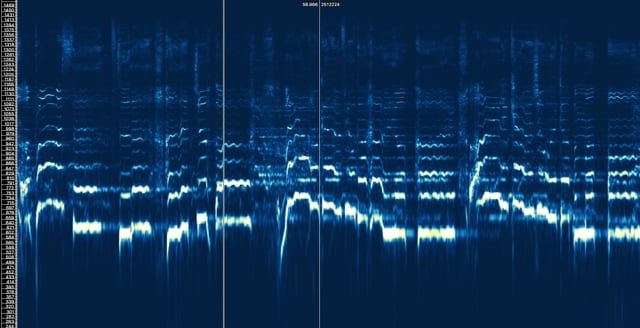
Color represents energy (dark = low, light = high) at specific frequencies in the audio spectrum. We can see that her voice is a complex mix of energy at many different frequencies all at once. We can basically “see” her voice.
I know the STFT doesn’t look like a cat… but… hear me out… It kind of is a picture… In the cat example, the neural network doesn’t actually know it is looking at a cat, it only knows that certain splats of color in specific sequences are “correct” because of its training. So, instead of cat pictures, why can’t we just feed a neural network a ton of STFT’s of Ariana Grande?
We can! And since we can transform these STFT’s back to audio we can use generative AI to make an audio track that sounds like Ariana Grande.
Of course, it is way more complicated than that, but I think it leads to a good way of thinking about ML problems. If you’re trying to solve a brand new thing with AI, a good way to start is to figure out how to transform your data into something an existing method can handle.
(all credit for this goes to an article on Towards Data Science I found while trying to write last week’s article about the Beatles. Check out “Audio AI: isolating vocals from stereo music using Convolutional Neural Networks” for a much better explanation of how all of this works.)